
[ 翻译 ] 软件架构和系统设计:我要是早点知道就好了……
【编者按】本文作者原本是一个不懂技术的人,在本文里,她分享了自己阅读 Artur Ejsmont 的《写给创业工程师的 Web 可扩展性》一书留下的读书笔记。
作为一个非技术人员,我总是在努力理解应用程序的底层实现。随着时间的推移,这方面有了很大改善:感谢各类书籍、文章、技术沙龙,我一些搞技术的朋友,当然,还有一位 Java 开发者,他同时也是我的丈夫 :)
 Hmm… 🤔
Hmm… 🤔
在这个故事里,我想推荐和回顾一本书,我认为对于没有任何技术背景或者相关教育经历(或者有,但是在实际的工作环境里不确定)的人来说都是必须一读的。这本书就是 Artur Ejsmont 编写的 “写给创业工程师的 Web 可扩展性”。尽管该书介绍的是有关 Web 应用程序的可扩展性,但是它实际上也解释了软件架构的核心概念和组件。这本书是如何的清晰明了简直无法用语言来形容!
重要笔记
这个故事完全是基于 Artur Ejsmont 的专业知识,我可不会在自己还没成为专家的时候假装自己是(至少现在还不是 😏 )。
我在这个故事里分享的内容非常有限。在看这本书的时候,我自己准备了一个长达 20 页的 Google Docs 摘要。如果你想要提高你对于软件架构的理解,我建议你看看这本书,准备一个摘要,然后和技术朋友或者同事讨论下你学到的东西。
要记住的一张图
Web 应用架构概览 (写给创业工程师的 Web 可扩展性, 2015, Artur Ejsmont, 第 23 页)
- 客户:你的 Web 应用程序的终端用户
- 域名系统( DNS ):基于一个域名( 例如 olgamitroshyna.com )定义了一个 IP 地址( 对应到将会处理用户请求的某台服务器的地址 )
- 负载均衡:在多台服务器之间分配流量以分担工作负载 3,5. 缓存:存储数据从而更快地响应用户请求
- 前端应用( Front-end ):这是用户接口,一个应用程序的皮肤,一个表现层
- 消息队列:存储用户请求以供 Web 服务作进一步的处理
- Web 服务( Back-end ):业务逻辑(应用程序功能)所处位置
- 数据存储:Web 服务写数据和读数据的地方
- 搜索引擎:响应数据存储无法有效处理的一些复杂搜索查询
- 内容交付网络( CDN ):存储像图片、CSS 样式和 JavaScript 文件等静态文件,让用户请求响应速度更快
- 队列工作者:使用一批额外的服务器来处理来自消息队列的请求(即消息)
前端层
前端层组件包括:
DNS;
CDN;
负载均衡/反向代理。可以是三种类型里的其中一种:
a) 一个托管服务( 比如亚马逊云提供的弹性负载均衡器( ELB ) ); b) 一个自维护的软负载均衡器( 比如 Nginx ); c) 一个硬件负载均衡器
前端 Web 服务器( 一个表现层以及后端结果的聚合层,用到的技术有:PHP、Python、Groovy、Ruby 或者 JavaScript( Node.Js ) )
同样重要的是要知道前端层通过以下方式来存储HTTP 会话相关的信息( 有关用户的数据 ):a) cookie; 或者 b) 外部数据存储;又或是 c) 如果是会话保持的场景那将会需要用到负载均衡器:负载均衡器需要确保具有相同会话 cookie 的请求始终被转发到最初发布该 cookie 的服务器。
后端层 / web 服务
实现一个 app 的几种选择:
- 构建一个单体的应用,然后根据业务需要增加 web 服务;
- 遵循 API 优先的设计理念:所有客户端( 移动端 app,桌面网站,移动端网站,等等 )和一个 Web 应用程序交互时使用的均是相同的一套 API 接口;
- 结合以上这两者
web 服务的类型:
- 以功能为中心
能够在远程机器上调用函数的一些方法,同时无需知道这些函数具体是如何实现的;
例子:SOAP( 使用 XML 和 HTTP 协议 );SOAP 比 REST 协议更复杂但也更安全,REST 在文档方面比 SOAP 更轻量一些
- 以资源为中心( REST + JSON )
各种资源被视为一个个的对象,然后针对这些对象可以执行四类操作:读取、创建、更新和删除( GET,POST,PUT,DELETE );
REST 需要通过认证来访问对应的资源( OAuth 2 );
取决于传输层的安全性( HTTPS )
扩展 REST 协议的 web 服务:
- 按照功能来分片/分区
一种将服务拆分成更小、独立的 web 服务的方法,其中每个 web 服务都专注于某项特定的功能;
各个 web 服务之间可能会存在一些依赖关系 —— 这没啥( 例如,当用户从目录里保存某些产品时,在用户( UserProfileService )和产品目录( ProductCatalogService )之间便建立了联系 );
每个 web 服务都可以独立扩展;
服务之间的整合可能会具有挑战性;
作者建议只有在技术团队超过 10~20 名工程师时才考虑使用面向服务的架构和 web 服务
增加克隆副本数
HTTP 协议缓存
当 GET 请求的响应被缓存时(当一个请求被应答时返回的是缓存里的数据而不再去问询 web 服务获得响应)
一些可扩展性的解决方案
- 增加更多的克隆副本/服务器( 最简单、最廉价的方式 );
- 按功能划分( 服务器专项化,采用面向服务的架构( SOA ),需要花费更多的精力,一些功能是受限的 );
- 按数据划分( 参见下面的 “数据层” 一段 )
数据层
传统的扩展方式 ——— 垂直扩展( 购买更强大的服务器,增加内存,添加更多的硬盘等 )。
扩展一个关系型数据存储( 例如 MySQL ):
- 复制同步
同一份数据创建出多个副本并分别存储在不同的机器上;
需要同步两台服务器之间的状态:源和副本;
数据修改 —— 仅通过源服务器执行相关的写操作,但是读取查询可以分布在多个副本之间;
复制同步的几点挑战:a) 只扩展读( 非常适合读密集型应用程序 );b) 不适用于解决一个活跃增长的数据集遇到的扩展问题;c) 副本可能返回过期的数据。
- 数据分区/分片
将数据集切分成更小的部分( 无需处理整个数据集 );
Sharding key 是分区的一个标准( 比如一个网店会有一些注册的用户,一个用户 ID 可以代表一个分片,所以任何用户相关的信息,比如订单,均会存储到那个分片上);
缺点:a) 加大了工作量和复杂性;b) 你无法跨多个分片执行查询;c) 视你如何根据 sharding key 映射到具体的服务器编号而定,有时候可能会很难再在基础设施里添加更多的服务器;
Azure SQL 数据库弹性扩展是一个随时可用的分片解决方案
NoSQL 扩展 ( 例如:Cassandra, Redis, MongoDB, Riak 以及 CouchDB ):
Eric Brewer 的 CAP 定理:不可能构建出一套同时满足一致性、可用性和分区容错性的分布式系统。
- 一致性:同样的数据同时对所有节点可见;
- 可用性:所有可用的节点都需要处理所有传入的请求并返回有效的响应;
- 分区:集群必须能够持续运转,尽管系统的各个节点之间可能存在任意数量的通信故障
这意味着一个分布式系统一次只能最多满足三个属性里的其中两个。比如 MongoDB 用可用性换取了一致性,它是一个 CP 数据存储。Cassandra 则是一个 AP 数据存储 —— 它提供可用性和分区容错性,但是不能保证 100% 的一致性。
当前的趋势:根据业务需求,按照功能划分出 web 服务层并对应采用不同的数据存储。
缓存
- 用于提高性能和可扩展性,因为它返回的是即时可用的结果;
- 尝试获取更高的缓存命中率( 即你可以重复利用相同的缓存响应多少次 );
- 缓存对于读频繁的应用程序很有用,但是对于写频繁的应用程序可能就没那么有效了;
- 如果需要,任何缓存都可以在后续阶段再加上
基于 HTTP 的缓存 —— 读穿透缓存( 这意味着客户端会和缓存通信,只有当缓存无法响应客户端时它才会请求 web 服务 )。
基于 HTTP 的缓存有以下几种类型:
- 浏览器缓存
我们将数据存储在浏览器里
- 缓存代理
通常是安装在公司的本地网络或是由互联网服务供应商( ISP )提供的服务器
- 反向代理 ( 例如 Nginx )
放在自己的数据中心,用来减少 web 服务器的工作负载;
它还是一种极好的扩展方式
- CDN
用来缓存像是图片、CSS样式、JavaScript、视频、PDF 等静态文件(但是如果有需要也可以提供动态内容)
自定义对象缓存:
- 缓存在客户端一侧的对象
存储在客户端的设备里
- 缓存和代码在一块
位于 web 服务器( 前端或者后端 );
对象可以直接缓存在:a) 应用程序的内存/RAM;b) 共享内存( 在同一台机器上运行的多个进程均可以访问到它们 );c) 缓存服务器可以作为一个单独的应用程序(相对于微型 Web 应用程序而言)部署在每台 Web 服务器上
- 分布式对象缓存
Redis, Memcached
异步处理
同步处理 —— 调用方发送请求后会一直等待直到返回响应才会继续原本的工作。您无法使用同步处理方式构建现代的响应式应用程序。
异步处理 —— 客户端可以在不知道请求是否被处理完成的情况下完成自己的工作,遵循"即发即忘"的原则。
消息队列是一种异步处理技术:
- 消息生产者 —— 客户端代码的一部分,创建消息然后将其发送到消息队列。
- 消息队列 —— 为消费者发送和缓冲消息的地方;
- 消息消费者 —— 接收和处理来自消息队列的消息。消息消费者的类型:a) 类似 cron 的循环作业(从队列中拉取消息); b)类似守护进程(推送模型)
消息平台:
- 亚马逊云的简单队列服务 ( SQS )( 简单、实用;创业早期的绝佳解决方案 );
- RabbitMQ( 提供了很多特性(包括复杂的路由),相当简单、灵活 );
- ActiveMQ( 基于 Java,延迟低很多,路由不太灵活,发布大量消息时可能会比较敏感 )
事件驱动型架构
- 不再是请求/响应模型,组件会声明已经发生的事件(而不是请求完成某项工作);
- 事件是一个指示某事发生的对象或消息;
- 我们的发布者和消费者对于彼此一无所知 —— 他们只知道事件消息的格式和含义。
搜索数据
- 一次全表扫描就是一次普通的查找( 需要扫描整个数据集才能找到目标数据 );
- 索引用于加快搜索速度:
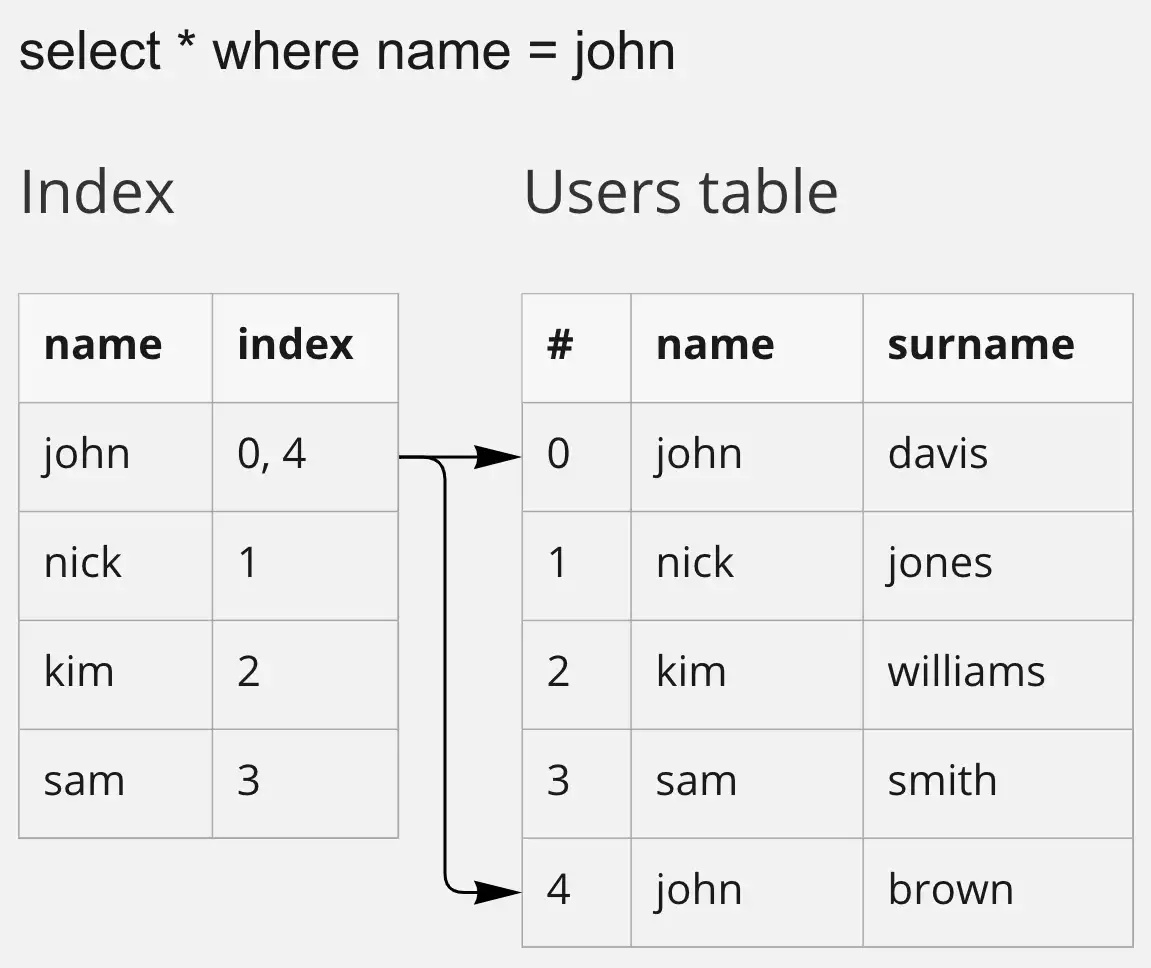 索引示例
索引示例
至于数据模型,关系型数据模型则是一些有关联的表的表现。在非关系型数据模型中,用户将会专注于用例并设计相应的查询,例如:返回一个产品集合(通常是一个包含产品列表的 JSON 数据)。
建议使用搜索引擎来完成复杂的搜索查询。他们通常使用允许搜索短语或单个单词的倒排索引。即用型搜索引擎包含:亚马逊云的 CloudSearch、Azure Search、Elasticsearch、Solr、Sphinx。
还有更多…
可扩展性不仅仅只受架构影响,还和下面这些有关:
各种流程的自动化(无论是测试、构建、部署流程、监控和告警,抑或是日志聚合);
扩展自己:
更聪明地工作,而不是更努力;
避免加班,因为它会导致精神问题和倦怠;
按优先级顺序管理任务,了解它们的真正价值;
构建简单、简约的功能;
委托代理;
分享知识,协作;
使用第三方服务,不要重新发明轮子;
协商最后期限( deadline );
小范围发布,收集反馈,不要想当然地去写代码;
为特定产品领域组建 4-9 人的小型跨职能自主团队( 例如聚焦于开发结账功能的团队 );
保持所有项目程序和标准的灵活性,因为它们会限制创造力和创新;
调整团队,设定共同目标,建立良好的工程文化;
书里面还有更多有用的建议!
结语
老实说,在看完 Artur Ejsmont 的《 写给创业工程师的 Web 可扩展性 》这本书后我松了一口气,因为我在工作中听到了很多关于软件架构和各种技术的信息,但我总觉得"我没有完全理解"。我想深入研究。我很高兴它发生了!
但是还有很多东西要学 🤓
感谢您阅读我的简短总结(真的很短,因为这本书包含了更多有价值的信息),希望你喜欢我的故事,也会喜欢这本书!
下次见!
原文链接:software-architecture-i-wish-i-had-known-about-this-earlier (翻译:Colstuwjx)