
[ 翻译 ] 借助 Linux 用户命名空间来增强容器安全性
Netflix 对于容器隔离性有着强烈需求,本文即介绍了他们技术团队在借助 Linux 用户命名空间以实现安全隔离性方面的探索。
之前在 Netflix 技术博客里也介绍过,Titus 是我们自研的一套容器编排系统。我们通过它来承载着公司各个部门的各种工作负载 —— 从 netflix.com 的前端 API,到机器学习训练工作负载,再到视频解码。在 Titus 里,实际运行这些工作负载的宿主机从用户的角度来看已经是被抽象了的。Titus 平台通过维护一定容量的同构节点的大池子来运行用户的工作负载,而 Titus 的调度器则会给这些工作负载做具体的分配调度。这样的抽象设计使得计算团队可以通过调度程序来调节整个舰队的可靠性、效能以及可操作性。运行工作负载的这些宿主机被称为 Titus 的 “agent”。在本文里,我们将会介绍 Titus agent 是如何利用 user namespace 来改善整个 Titus agent 舰队的整体安全性。
Titus 的多租户集群
在用户看来,一个 Titus agent 舰队即是一个同构的容量池,Titus 在内部采用的是一个蜂窝式的隔板架构,这样可以实现可扩展性,因此,整个舰队实际上是由多个单元组成。许多隔板架构基于多租户来划分单元,这里面的租户被定义成一个团队以及他们的一组应用集合。我们并没有采用这套方案,取而代之的是,我们“将这些单元划分成均衡的负载”。之所以这样做,主要是出于可靠性、可伸缩性和效率的原因。
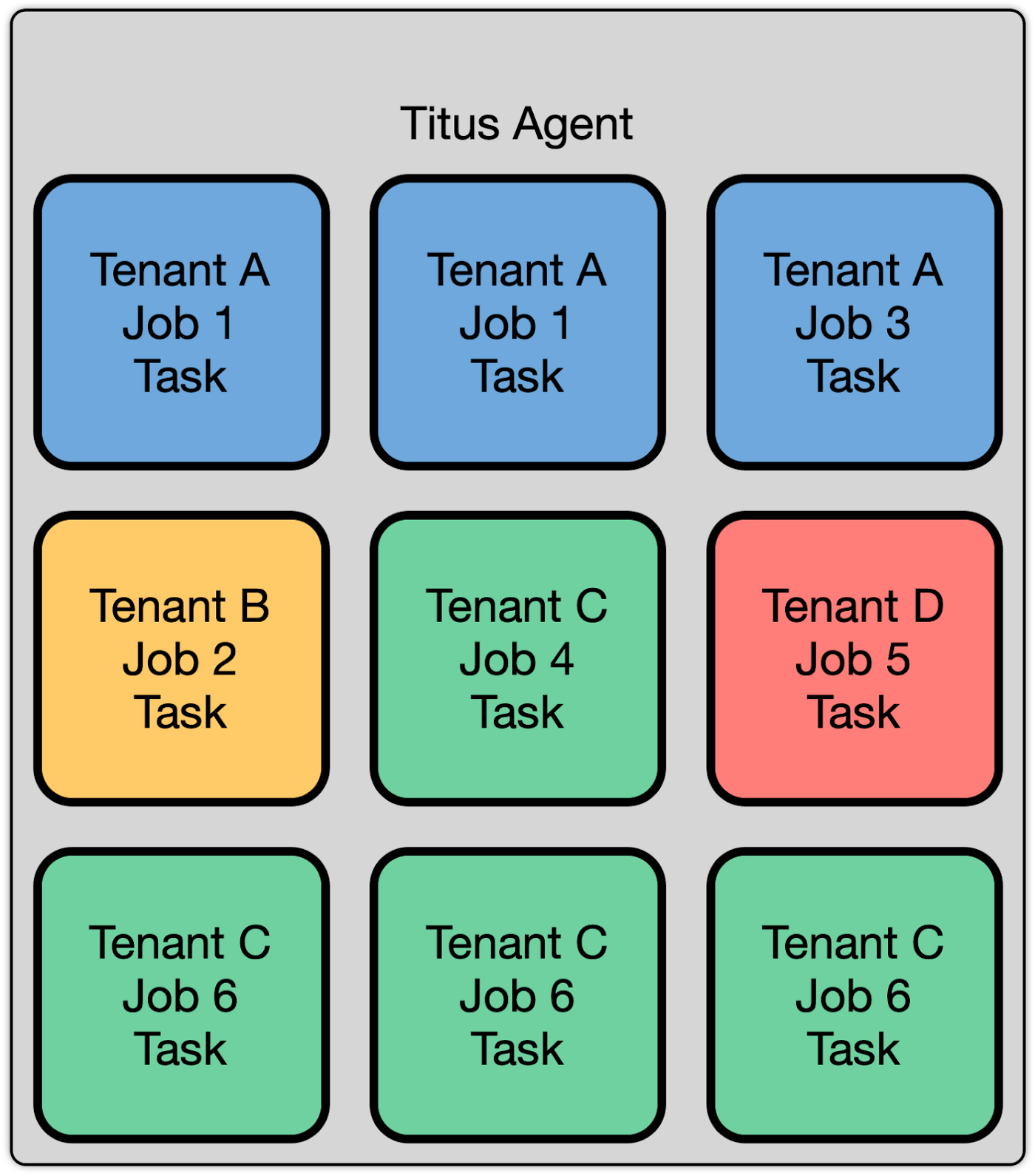
Titus 是一套支持多租户的系统,它允许多个团队和用户在系统上运行他们的工作负载,然后它会确保它们可以共存,同时仍然确保有关安全性和性能的要求。这其中大部分是通过隔离实现的,形式多种多样。这些形式包括性能隔离(确保这些工作负载之间不会受到彼此之间的影响而降低性能),容量隔离(确保一个给定的租户在需要时可以获得需要的资源),故障隔离(确保系统的局部故障不会导致整个系统瘫痪),以及安全隔离(确保一个租户的工作负载受到损害时不会影响到其他租户的安全性)。在这篇文章里,我们将重点介绍我们的安全隔离方案。
给多租户做安全加固
Titus 在多租户方面最大的担忧之一便是安全隔离性。我们希望能够允许来自不同租户的不同种类的容器能够在相同的实例上运行。容器的安全隔离性一直是一个有争议的话题。尽管存在风险,我们仍然还是选择了利用容器作为安全边界的一部分。为了消除将容器作为安全边界所带来的诸多风险,我们采取了一些额外的保护措施。
多租户的基本构成便是 Linux 命名空间,这是让 LXC、Docker 和其他类型容器具备技术可行性的基础。举个例子,PID 命名空间可以让一个进程只能看到属于它自己的命名空间里的进程 PID 列表,也因此,它无法给宿主机上的随机进程发送 kill 信号。除了 Docker 默认支持的一些命名空间(mount、network、UTS、IPC 以及 PID),我们还通过用户命名空间(user namespace)增加了一层额外的隔离。不幸的是,难免仍然会出现像 CVE-2015–2925 这样的安全漏洞,这些默认的命名空间的边界不足以防范容器逃逸问题。这些漏洞的出现主要是因为命名空间之间存在的复杂交互,内核开发过程中大量的历史决策,以及像 Linux 里面的 proc 文件系统之类的有瑕疵的抽象所导致的。如何正确组合这些安全隔离的原语实际上相当困难,因此,我们转而寻求其他层面的额外保护措施。
在一台宿主机上以多租户的形式运行许多不同的工作负载时必须得提防横向移动问题,这种技术也即是攻击者在攻破了运行在宿主机上的某个容器里的单个软件后,利用该软件攻破了同一系统上的其他容器。为了减少这样的情况,我们以非特权用户来运行容器 —— 这样做它就无法使用 “root” 用户了。这一点很重要,因为在 Linux 里,UID 0(或者说拥有 root 权限),事实上并非只是来自于 root 这个用户,这实际上是一组 Linux capability。这些 capability 会关联到当前进程的会话凭证。capability 可以通过提权(比如 sudo,设定 capability)的方式添加,也可以被移除(比如 setuid,或者切换命名空间)。各种 capability 会控制 root 用户能做什么。举个例子,CAP_SYS_BOOT capability 控制一个给定的用户能否重启机器。这里还有很多更常见的 capability 可以被分配给用户,比如 CAP_NET_RAW,它赋予一个进程打开原始套接字的能力。用户可以通过书写 capability 的方式实现在执行某些指定文件时自动赋予一些 capability。比如,在一个现成的 Ubuntu 系统里,ping 命令需要 CAP_NET_RAW :
sargun@ubuntu:~$ getcap $(which ping)
/bin/ping = cap_net_raw+ep
CAP_SYS_ADMIN 是 Linux 中最强大的 capability 之一,它实际上等同于具备有超级用户的访问权限。它赋予了用户执行所有操作的能力,从随意挂载文件系统,到访问可以公开 Linux 内核相关重要信息的跟踪点 (trace point)。另一些强大的 capability 还包括 CAP_CHOWN 和 CAP_DAC_OVERRIDE,拥有这些能力的话便可以操纵文件权限。
在内核里,你将会经常看到这些 capability 检查遍及整套代码,它们看上去会是下面这样:
static int pcrlock(const int pcrnum)
{
if (!capable(CAP_SYS_ADMIN))
return -EPERM;
return tpm_pcr_extend(chip, pcrnum, digests) ? -EINVAL : 0;
}
注意,该函数不会检查用户是否是 root,而是会在它执行前先检查一下该任务是否具备 CAP_SYS_ADMIN capability。
Docker 采用的方案则是使用一个 allow-list 来定义一个容器可以接收哪些 capability 。这些可以由用户来扩展或者削弱。在某些情况下,Docker profile 里的一些默认能力也可能会被滥用。当我们使用一个不具备这么些 capability 的非特权用户试着去运行这些工作负载的时候,我们会发现这行不通。各种软件或多或少均有在 FUSE、底层数据包监控以及性能跟踪等其他用例中使用了增强后的 capability。程序的启动通常都将伴随着一组 capability,它会执行多个需要这些 capability 的任意活动,然后在进程不再需要它们的时候 “丢掉” 它们。
用户命名空间
幸运的是,Linux 有一个解决方案 —— 用户命名空间。我们不妨回到之前的内核代码示例。pcrlock 函数会调用 capable 函数来确定该任务是否有能力。此函数会定义成:
bool capable(int cap)
{
return ns_capable(&init_user_ns, cap);
}
它将会检查该任务是否具备相关的 capability 来执行 init_user_ns。init_user_ns 是最初产生这些进程的命名空间,因为它是内核启动时存在的唯一的用户命名空间。用户命名空间是一种用来用于分隔 init_user_ns UID 空间的机制。设置这个映射的接口是一个通过 /proc 对外暴露的 “uid_map” 和 “gid_map”。具体映射关系如下所示:
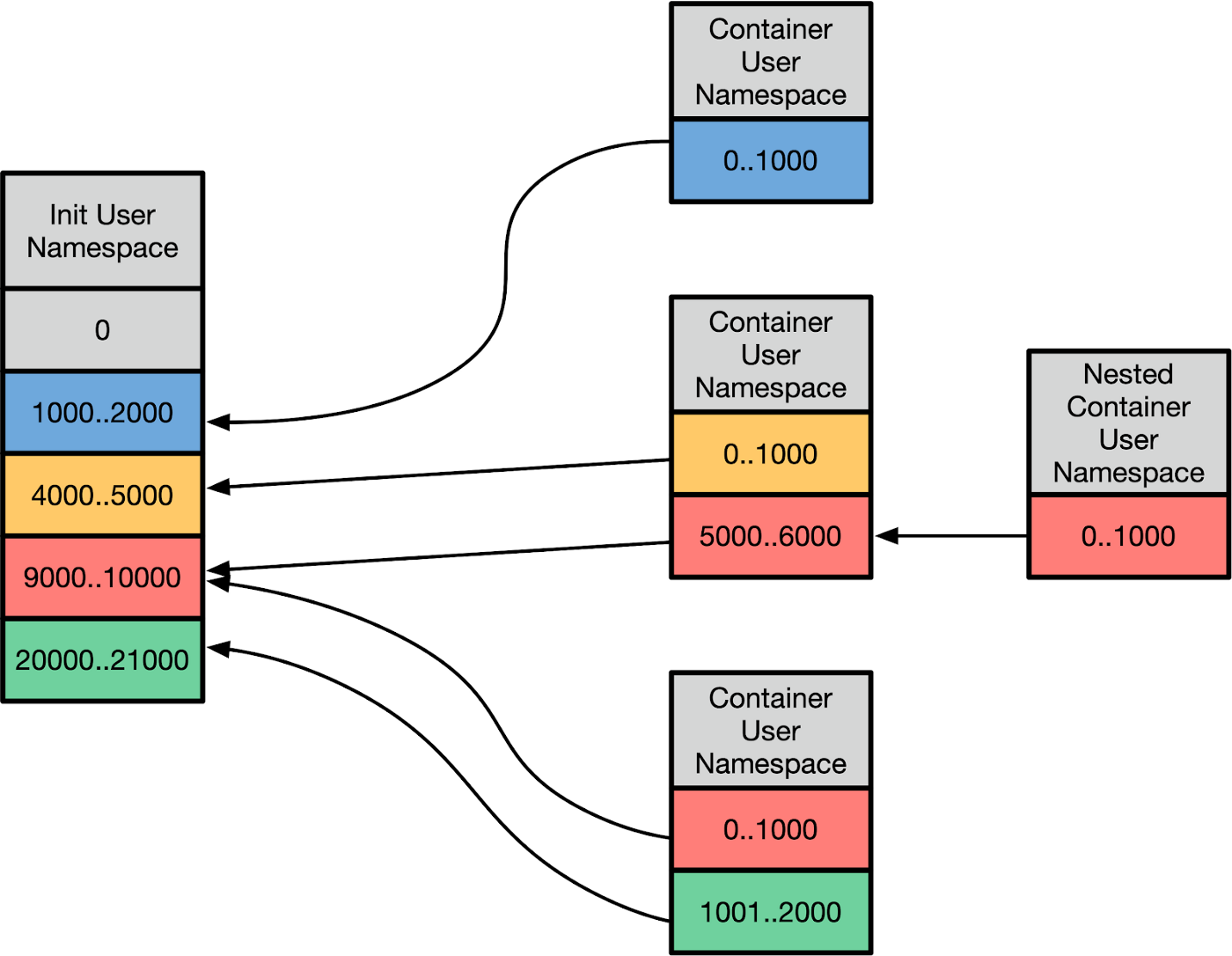
它允许将存在于不同用户命名空间的各个容器的 UID 逐一映射到宿主机上的 UID。这中间经过了各种翻译转换,但是从容器的角度来看的话,所有内容都是以映射后的 UID range(也被称为 extent )的角度来看的。它的强大表现在多个方面:
它允许你为容器设置某些 UID 禁区 —— 假设一个 UID 不在用户命名空间到真实 UID 的映射范围里的话,你如果尝试通过它来检索磁盘上的文件,该文件将显示为 overflowuid/overflowgid,一个在 /proc/sys 里的特定 UID 和 GID,以此表明它是无法被映射到当前工作空间的。再者,容器也无法再通过 setuid 设置一个 UID 的方式来访问这些被那个 “外部的uid” 拥有的文件。
从用户命名空间的角度来看的话,容器的 root 用户似乎是 UID 0,而且容器可以使用映射到该命名空间下的整个 UID 范围。
然后,内核子系统可以继续通过绑定到资源的特定用户命名空间来调用 ns_capable。如今,许多的 capability 检查发生在和这些要操作的资源相关联的一个用户命名空间里。反过来,这也使得这些原本在初始用户命名空间里并没有任何权限的进程得以行使某些特权。即便在众多不同的命名空间里有着相同的映射关系,capability 检查仍然可以针对特定的某个用户命名空间进行。
理解这套权限系统如何工作的一个关键要点在于每个命名空间都从属一个特定的用户命名空间。举个例子,我们不妨看看 UTS 命名空间,它负责控制 hostname:
struct uts_namespace {
struct kref kref;
struct new_utsname name;
struct user_namespace *user_ns;
struct ucounts *ucounts;
struct ns_common ns;
}
该命名空间和一个指定的用户命名空间存在一个关联关系。一个用户是否能够操作主机名,取决于该进程在它的用户命名空间里是否具备相关的 capability。
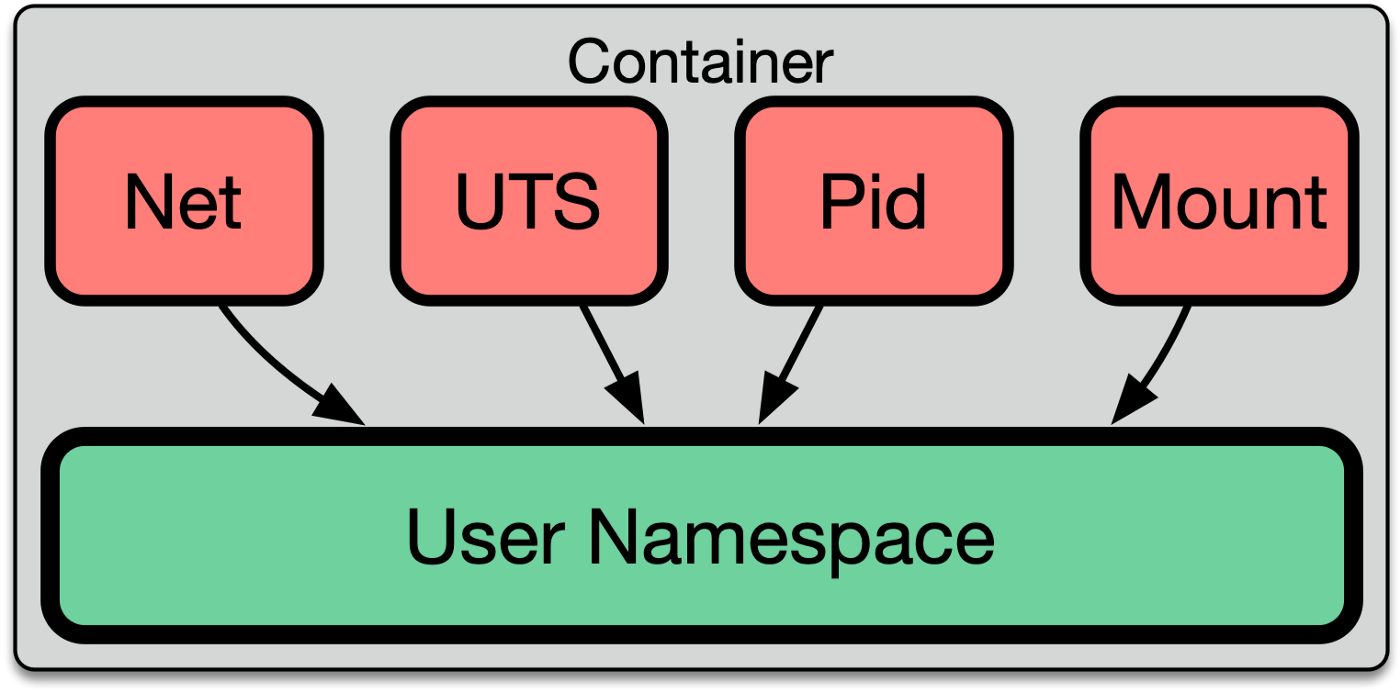
继续深入
我们可以探索一下命名空间和用户本身的工作之间是如何交互的。想要在 UTS 命名空间里设置主机名的话,你需要在它的 user namespace 里拥有 CAP_SYS_ADMIN 能力。我们可以在下面的实际操作中验证这一点,在下面的例子里,一个无特权的进程没有权限设置主机名:
sargun@ubuntu:~$ id
uid=1000(sargun) gid=1000(sargun)
sargun@ubuntu:~$ strace -e trace=sethostname hostname foo
sethostname("foo", 3) = -1 EPERM (Operation not permitted)
hostname: you must be root to change the host name
+++ exited with 1 +++
之所以出现这样的情况,原因就在于该进程不具备 CAP_SYS_ADMIN 的能力。根据 /proc/self/status 展示的情况,此进程的有效能力集为空:
sargun@ubuntu:~$ capsh --decode=$(gawk -F':\t+' '$1 == "CapEff" { print $2; }' /proc/$$/status)
0x0000000000000000=
现在,让我们尝试设置一个用户命名空间,然后看看会发生什么:
sargun@ubuntu:~$ unshare --map-root-user --user
root@ubuntu:~# id
uid=0(root) gid=0(root) groups=0(root),65534(nogroup)
很快,你将会注意到命令提示符提示说当前用户是 root,然后 id 命令对此也表示赞同。那么,现在我们可以设置主机名了吗?
root@ubuntu:~# strace -e trace=sethostname -e 'signal=!all' hostname foo
sethostname("foo", 3) = -1 EPERM (Operation not permitted)
hostname: you must be root to change the host name
+++ exited with 1 +++
好吧,我们依然无法设置主机名。这是因为该进程仍然处于初始的 UTS 命名空间里。让我们来看看是否可以取消 UTS 命名空间的共享,然后设置一下主机名:
root@ubuntu:~# strace -e trace=unshare -e 'signal=!all' unshare --uts
unshare(CLONE_NEWUTS) = 0
root@ubuntu:~# strace -e trace=sethostname -e 'signal=!all' hostname foo
sethostname("foo", 3) = 0
+++ exited with 0 +++
root@ubuntu:~# hostname
foo
大功告成,而且该进程如今已经处于一个主机名叫做 “foo” 的隔离后的 UTS 命名空间里。这是因为该进程现在已经具备了一个传统的 root 用户理应拥有的所有 capability,前提是相对于我们所创建的这个新的用户命名空间而言:
root@ubuntu:~# capsh --decode=$(gawk -F':\t+' '$1 == "CapEff" { print $2; }' /proc/self/status)
0x000001ffffffffff=cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend,cap_audit_read
如果我们从外部检索该进程信息的话,可以看到该进程仍然是以一个非特权用户的身份运行,而原本外部的命名空间里的主机名并未更改过:
root@ubuntu:~# echo $$
130938
# Switched back to initial namespace session
sargun@ubuntu:~$ ps u 130938
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
sargun 130938 0.1 0.1 15188 8736 pts/2 S+ 02:05 0:00 -bash
sargun@ubuntu:~$ hostname
ubuntu
基于此,我们可以做很多事情,比如挂载文件系统,创建另外一些新的命名空间,而且实际上,我们可以基于此搭建出一整套的容器环境。注意,在执行任何这些操作的过程中我们并没有使用任何提权的机制。这一方案被一些人称之为 “rootless containers”
落地之路
我们从 2017 年初开始启动用户命名空间的相关工作。当时我们设想了一个更为简单却又不太成熟的模型。之所以如此简单是因为我们是在未启用用户命名空间的情况下运行的:
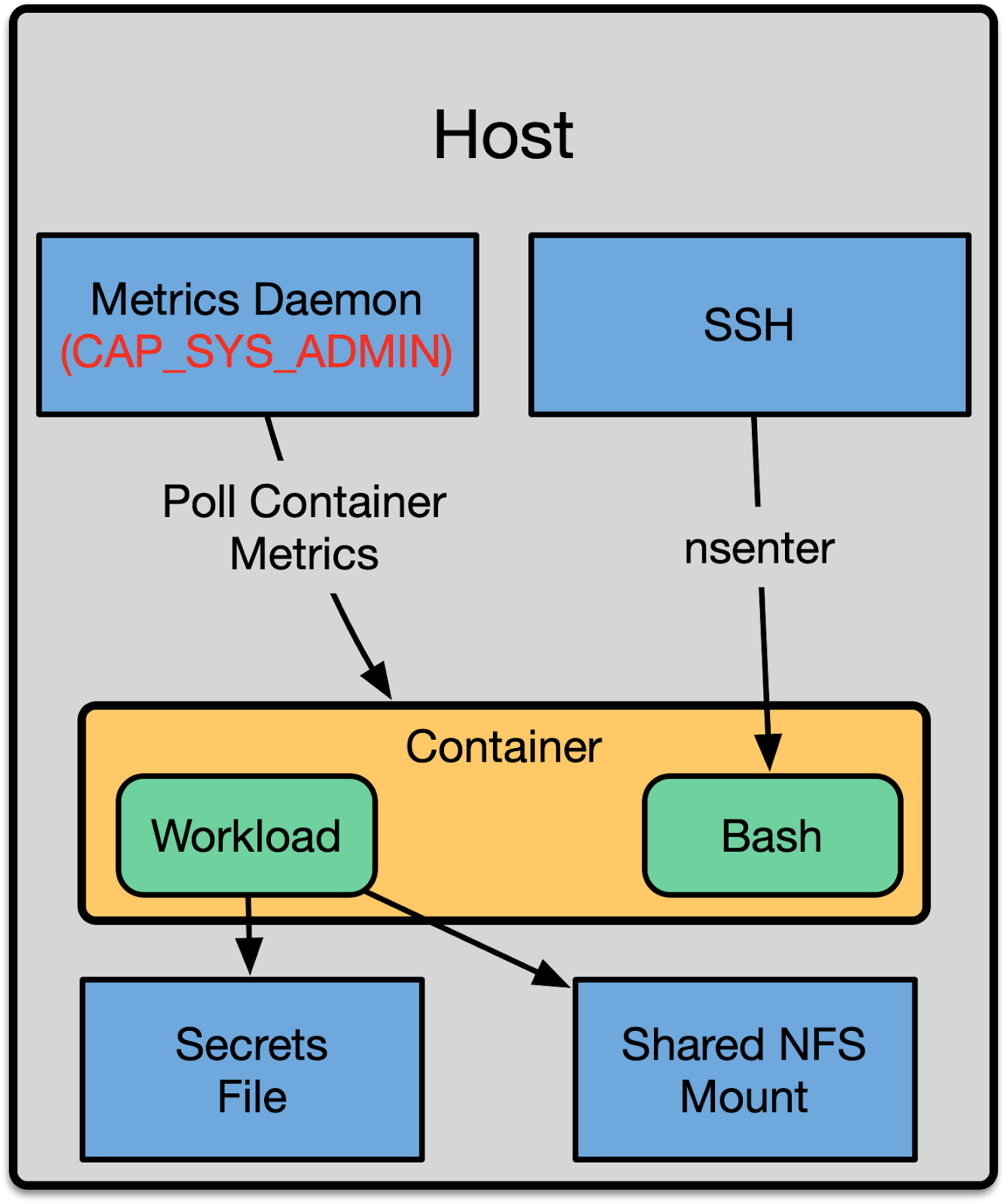
该方案会镜像一份现代容器编排系统的进程布局及边界。我们在机器上会部署一个共享的监控采集客户端,它会进入容器里然后采集相关的指标。用户可以通过宿主机上对外暴露的一个 SSH 守护进程来访问容器,然后它会在用户执行相关操作时自动通过执行 nsenter 的方式将这些操作透传到容器里。要将文件暴露给容器的话,我们将会用到 bind mount。同样的机制也被用于暴露配置,比如 secret。
这样做的好处是,我们可以把许多软件安装在宿主机的命名空间里,然后只需要管理该命名空间下的文件。之后,容器运行时管理系统(Titus)会负责配置 Docker,通过 bind mount 的形式将对应的文件暴露给容器。除此之外,我们可以在宿主机上使用我们标准的监控采集客户端程序。
尽管这一模型很容易构思和编码实现,但是它仍然存在一些短板,这些缺陷我们是通过将所有内容转移到容器里一个非特权的用户命名空间里运行来解决的。第一个缺陷便是宿主机上所有的守护进程都需要感知到 UID 转换,并且需要正确地执行相关的 setuid 或者 chown 操作用以跨容器边界转换。其次,每一处这样的转换都意味着一个潜在的安全风险。如果 SSH 守护进程仅仅通过更改为容器的 pid 命名空间这样局部地转换到容器命名空间里的话,它会让它的 /proc 仍然可以被访问到。之后,某个恶意攻击者便可以利用它来逃脱。
使用用户命名空间的话,我们可以通过在容器的非特权用户命名空间里运行这些守护进程来改善我们的安全状况并且降低系统的复杂性,这就避免了跨命名空间边界。反过来,这也消除了正确实现跨命名空间转换机制的需要,从而减少了引发容器逃逸的风险。
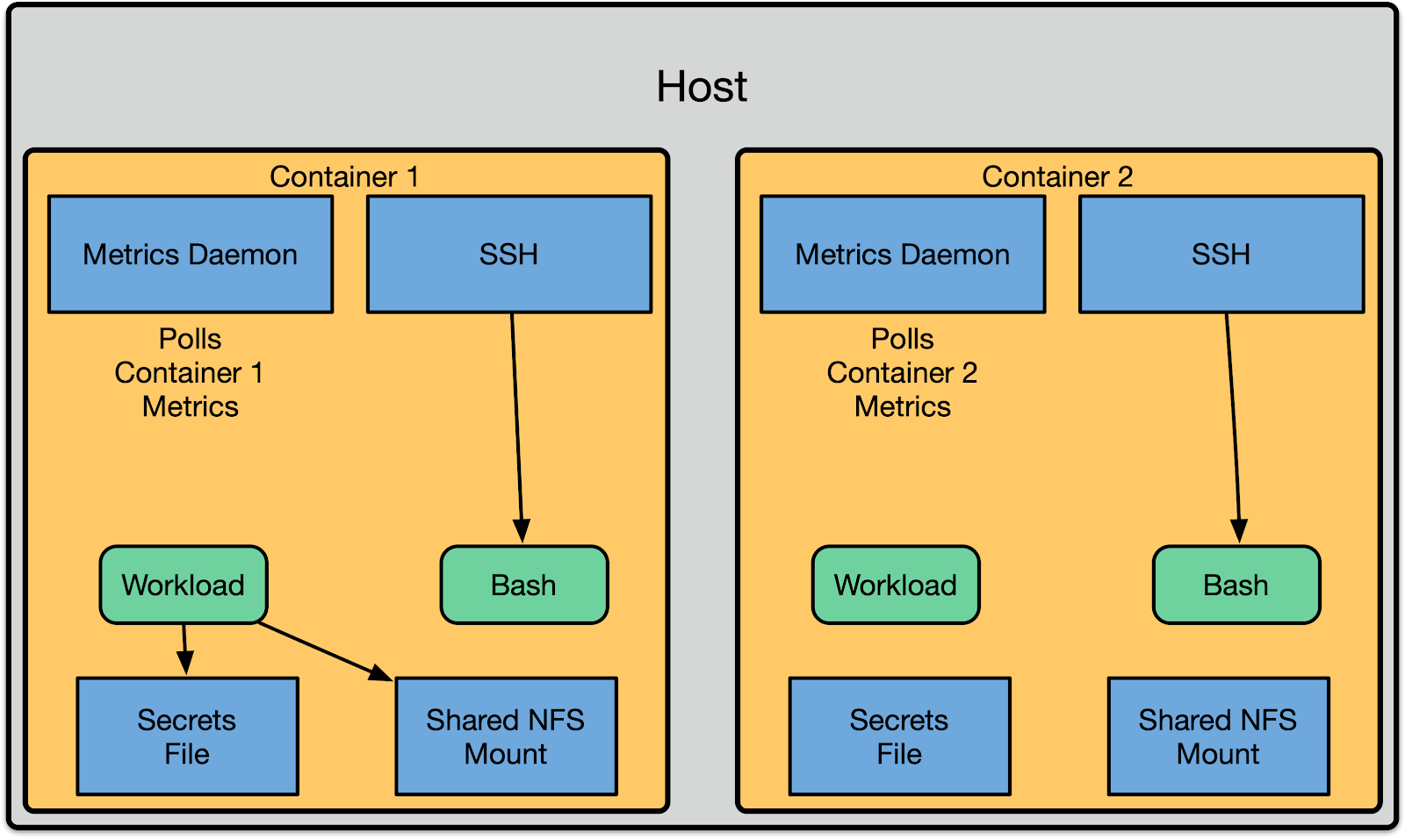
为此,我们把容器运行时环境的各个部分都挪到了容器里。比如,我们会为每个容器运行一个 SSH 守护进程以及一个监控采集客户端。它们会运行在容器的命名空间里,并且和容器里的工作负载拥有相同的 capability 以及生命周期。我们把这一模型称之为 “系统服务” —— 人们可以将其视之为一个 Pod 的原始版本。到 2018 年底,我们已经成功将所有容器迁移至非特权的用户命名空间里运行。
用武之地?
这似乎又是一个中间层,它会引入额外的复杂性,但是取而代之的是,它使得我们得以实践一个非常有用的概念 —— “非特权容器”。在这些非特权的容器里,root 用户基于一个基准线启动,在该基准下,它们无法自动被授予相关权限来访问整个系统。这意味着 DAC、MAC 以及 seccomp 策略现如今会是防止恶意获取系统特权方面的一个额外保护层 —— 而不再只是唯一的一层。新的特权被赋予后,我们无需再将它们加到一个排除列表里。这就使得我们的用户可以编写相关的软件,在这里他们可以操控自己容器的底层系统细节,而无需将所有的复杂性强加到容器运行时里。
用例:FUSE
Netflix 内部使用了一个专用的名为 MezzFS 的 FUSE 文件系统。该文件系统的目标是让各种编码工具得以访问我们的内容。这些编码工具中的绝大多数都是设计用于和 POSIX 文件系统 API 做交互。我们的媒体云工程团队希望利用容器来构建一套他们之前构建的平台的全新版本,也即是 Archer。Archer,反过来,它也用到了 MezzFS,换句话说也即是需要 FUSE,而在当时,FUSE 要求用户在初始用户命名空间里拥有 CAP_SYS_ADMIN capability。当时为了适配我们内部小伙伴的用例,我们不得不在一个专用集群里运行它们,在这些集群里它们可以运行特权容器。
2017 年,我们同合作伙伴 Kinvolk 展开了一次合作,给 Linux 内核打了一些补丁,使得用户可以基于一个非初始用户命名空间安全地使用 FUSE。他们成功地将这些补丁反馈到了上游,而我们也一直在生产环境里使用它们。从用户的角度来看,我们得以将它们无缝地迁移到一个更安全的非特权环境里。由于不必再将这类工作负载视为例外,这也大大简化了相关操作,并使得它们可以同通用节点池中所有其他的工作负载一起运行。结果便是,由于部署的同质性,这也使得我们的媒体编码团队得以消费共享集群里海量的计算能力,可靠性也变得更高了。
用例:意外的特权行为
在过去几年里,业内已经发布了不少因为意外授予容器不必要的特权造成的 CVE 漏洞:
CVE-2020–15257:containerd 的特权提升
CVE-2019–5736:通过覆盖宿主机上的 runc 二进制文件进行特权提升
CVE-2018–10892:访问 /proc/acpi,使得攻击者得以修改硬件配置
不难想象,每个快速发展的复杂系统均会如此,将来肯定还会出现更多的漏洞。我们已经采用了 Docker 所提供的一些默认设置,比如 AppArmor 和 seccomp,但是通过引入用户命名空间,我们得以实现一套更高级的深度防御安全模型。这些 CVE 漏洞不会对我们的基础架构产生影响,因为我们正将用户命名空间推广到所有容器。初始用户命名空间的 capability 削减工作也是如期进行,并成功阻挡了这些攻击。
未来
内核里仍然有许多部分正在加入对用户命名空间的相关支持和增强,这让用户命名空间变得更易于使用。剩下要做的许多工作大都集中在文件系统和容器编排系统它们身上。这其中一部分改进会在即将发布的内核版本中带上。添加 支持 overlayfs 非特权挂载的工作即将完成,它将允许用户在多个分层的用户命名空间里做嵌套的容器构建。后续工作的重点会放在让 Linux 内核的 VFS 这一层原生感知到 ID 的转换。这将会让不同 ID 映射的用户命名空间能够通过在 bind mount 中移动 UID 的方式来访问同一套底层文件系统。我们在 Kinvolk 的合作伙伴还致力于将用户命名空间引入到 Kubernetes 。
如今,各种容器运行时均已加入了对用户命名空间的支持。根据 Docker 文档里所描述的,它可以通过设置一个机器范畴的 UID 映射,为每个容器分配一个单独的用户命名空间。任何兼容 OCI 标准的容器运行时,比如 Containerd/runc 、Podman 以及 systemd-nspawn 均支持用户命名空间。各种容器编排引擎还通过它们底层的容器运行时添加了对用户命名空间的支持,比如 Nomad 和 Docker Swarm。
作为我们转向 Kubernetes 的一部分,Netflix 一直在与 Kinvolk 合作,让用户名称空间得以在 Kubernetes 下工作。你可以通过这里的 KEP 讨论来跟踪这项工作的进展,Kinvolk 在他们博客里还介绍了更多有关如何在 Kubernetes 下运行用户命名空间的详细信息。我们期待与 Kubernetes 社区一起发展容器安全性。