
[源码分析] 解读 Kubernetes EndpointSlice 控制器导致的Crash 问题始末
前几天看到华为云容器团队维护的公众号 “容器魔方” 发布的一篇文章,里面提到了一个 EndpointSlice 相关的 Bug ,官方人员也很快就提了修复的PR。笔者近期也一直在关注这块功能, 今天就分析一下这个 Bug 以及相关修复的 PR 内容。
什么 Bug ?
华为云文章里对这个 Bug 的介绍如下:

上面也给出了这个 Bug 的修复PR 85368,一路追查起因,可以发现最初是 RainbowMango (这位大佬应该是华为云团队的一员)在另外一个PR 83837里的测试用例发现的问题。
关于 k8s 的测试
关于 k8s 的测试,需要一个系列的文章来完整介绍,这里我们只需要知道每个提交到 k8s 仓库的 PR ,只需要满足:
1、发起人是 k8s member ;
2、有 k8s member 审阅后追加了/ok-to-test
这两者之一,就会自动触发 k8s 的测试基础设施发起一次自动化测试任务,它会根据当前PR修改的内容,自动定制一份需要执行的测试列表,用户也可以在评论区通过追加 /test xxx 的评论内容来手动触发相关的测试任务。
共享内存导致的问题
回到问题,根据测试失败结果,这位大佬在评论里同步了相关异常信息:在执行 /test pull-kubernetes-kubemark-e2e-gce-big 这个测试任务时,k8s 的核心组件之一,kube-controller-manager panic 了,日志显示 fatal error: concurrent map iteration and map write ...,具体报错内容见这个PR 83837里的评论内容。
先简单 Google 一下这个 Golang 的报错,不难知道这是一个 map 被一个线程遍历的同时存在另外一个线程对该 map 执行了写操作导致的 panic 。
那么这是哪里报出来的 panic 呢?从上面的链接里的报错日志,不难发现最后一次业务逻辑层的调用是在这里:
k8s.io/kubernetes/pkg/controller/endpointslice.(*Controller).ensureSetupManagedByAnnotation(0xc0009bc4e0, 0xc00c171e00, 0xc00569faa0, 0x0)
pkg/controller/endpointslice/endpointslice_controller.go:414 +0x4ba fp=0xc0015ebac8 sp=0xc0015eb8c0 pc=0x245d99a
那么这个方法为什么会导致上述的 panic 呢?RainbowMango 大佬另外开了一个 issue 85331 来专门汇报这个 Bug,并且贴出了触发 panic 的上述代码执行的方法体部分:
for _, endpointSlice := range endpointSlices {
if _, ok := endpointSlice.Labels[discovery.LabelManagedBy]; !ok {
if endpointSlice.Labels == nil {
endpointSlice.Labels = make(map[string]string)
}
endpointSlice.Labels[discovery.LabelManagedBy] = controllerName
_, err = c.client.DiscoveryV1beta1().EndpointSlices(endpointSlice.Namespace).Update(endpointSlice)
if err != nil {
return err
}
}
}
if service.Annotations == nil {
service.Annotations = make(map[string]string)
}
service.Annotations[managedBySetupAnnotation] = managedBySetupCompleteValue
// 这一行报出的panic!
_, err = c.client.CoreV1().Services(service.Namespace).Update(service)
return err
而在这个方法的开头,EndpointSlice 功能的开发 robscott 也写了一些注释:
// ensureSetupManagedByAnnotation selects all EndpointSlices for a Service and
// ensures they have LabelManagedBy set appropriately. This ensures that only
// one controller or entity is trying to manage a given EndpointSlice. This
// function provides backwards compatibility with the initial alpha release of
// EndpointSlices that did not include these labels.
// TODO(robscott): Remove this in time for v1.18.
这表明这个方法是出于向后兼容性而存在的,它会判断一个 Service 下的 EndpointSlice 是否都具备 LabelManagedBy 标签,如果没设置此标签的话,该方法将会默认给对应的 EndpointSlice 打上 LabelManagedBy 标签并且值为 controllerName 的值,也就是表明这些 EndpointSlice 由 endpointslice-controller.k8s.io 管理的意思。
除了更新 EndpointSlice 对象的标签内容,这个方法还操作了 service 的 annotation ,见下面代码:
if service.Annotations == nil {
service.Annotations = make(map[string]string)
}
service.Annotations[managedBySetupAnnotation] = managedBySetupCompleteValue
// 这一行报出的panic!
_, err = c.client.CoreV1().Services(service.Namespace).Update(service)
根据 managedBySetupCompleteValue 和 managedBySetupCompleteValue 的注释内容,可以得知,为了标明此 service 下的 endpoints 均已经被处理过,此方法给每个处理过的 service 增加了对应的 annotation 字段。也正是更新 service 这一步触发的 panic。
很显然,根据 panic 信息可以判定,在更新这个 annotation 的同时,有其他 goroutine 在遍历这个 service.Annotations。这也解释了为什么这个 Bug 是 有概率触发 的,而不是一定每次复现的。
那么,为什么会导致这个问题呢?不难想到,这个 service 应该是一个指针类型,然后有其他地方也用到了该指针的数据,k8s 的核心开发 thockin 也指出了问题的根源,并且提出了可以通过 DeepCopy() 做一次深拷贝的方式来解决这个问题:
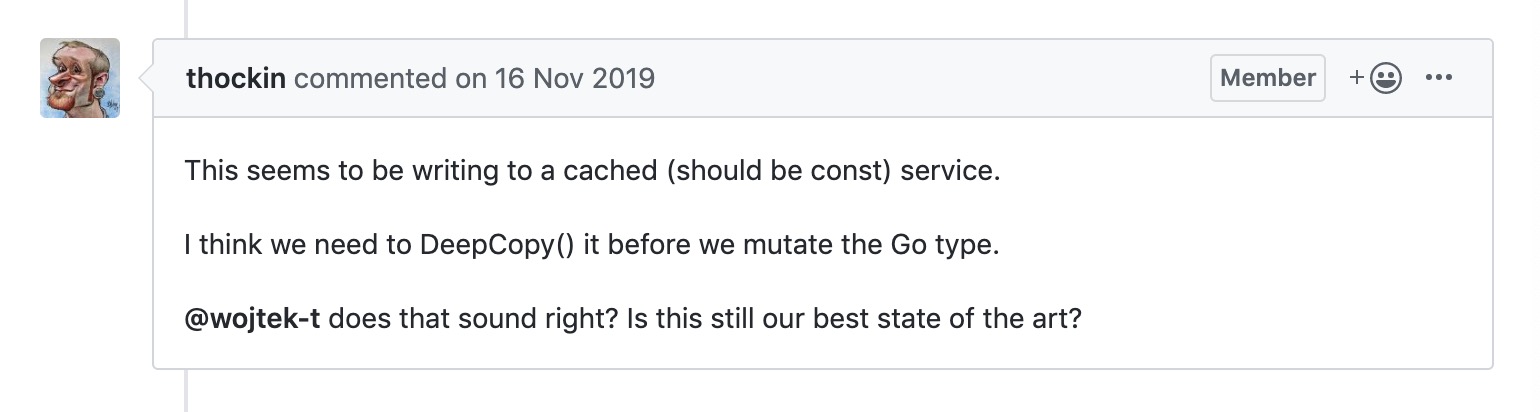
而官方开发人员 liggitt 进一步提出了可以通过 cache mutation detector 来检测这类操作。
OK,问题分析就到这了。
怎么解决?
关于上面 issue 报出的这个panic,负责 EndpointSlice 功能开发的 robscott 也很快就这个问题提出了一个修复的 PR 85359,等于是把 ensureSetupManagedByAnnotation 部分 revert 掉了。这期间 robscott 和 liggitt 还各自提了一个 PR 85324 、PR 85356 尝试修复,因为最终没合并,这里就不再赘述了。
除了修复这个问题以外,liggitt 又紧接着提了一个PR,启用了 mutation detection的测试验证。通过这个测试,又找出了一个EndpointSlice 控制器操作的共享变量问题,原因也是类似的,因为 addTriggerTimeAnnotation 方法对原共享对象 endpointslice的注解做了写操作。很快,robscott 又提了一个 PR 85368 ,通过 DeepCopy() 的方式修复了这个问题,并且通过在测试用例里增加 CacheMutationCheck 的方式从测试途径每次验证这一点。
关于 CacheMutationCheck 这个工具库的实现原理也很简单,就是在最开始先深拷贝一份源对象,然后再在后面通过 reflect.DeepEqual 来比较该对象是否发生过修改。
至此,这个 panic 问题终于得到了完全的修复,一些隐患也通过测试的方式找出并修复了,并且通过启用 cache mutation detector 等方式也可以避免重复踩坑,完美!
后记
在完成这个问题的通篇分析后,个人有几点收获和理解:
kube-controller-manager 有变得越来越复杂的趋势,各种核心逻辑的controller 集成到这里增大了出现 Bug 的风险;
华为云文章里提到的PR其实并不是真正修复这个panic问题的PR,这也让笔者意识到,很多东西要带着辩证的态度去看待,到底是怎样的,先不要着急下结论,分析和调研一下再说;
测试是必不可少的环节,这次问题之所以没有在早期暴露出来,很大程度就是 EndpointSlice 缺少了这块的测试覆盖(不过话说如果加了这块也说明开发自己意识到了这块潜在可能出问题…);
共享内存应当小心谨慎地对待,当你要对它做写操作时,尤其要注意,多想想自己是否真的清楚,有谁在消费它,自己修改它的后果。
结束!