
记一次失败的docker排障经历
这是一次失败的排障经历…
掐指头一算,从14年年中GL总介绍Docker这个项目以来,鄙人实际开始玩Docker也有2年多了,说是玩,其实对它本身的一些原理性质的东西还不够清晰,而且也没做到“玩转”的水平(业内其实有很多玩Docker的案例了,比如大浪同学玩转razor with docker,还有谷歌大神 All in Docker)等等。
Okay,闲话不多说,本文即是介绍鄙人最近(2017.06.03)对docker daemon无故hang住问题的一次排障经历。这一问题其实存在已久,因为没有足够的精力,对Docker也不够熟悉(其实还是惰性使然,这种排障投入产出比太低了,所以很多时候倾向于workaround),因此直到这回才真正深入挖掘了一下,当然,见于标题所述,其实这回也是一次失败的尝试 :(
版本信息
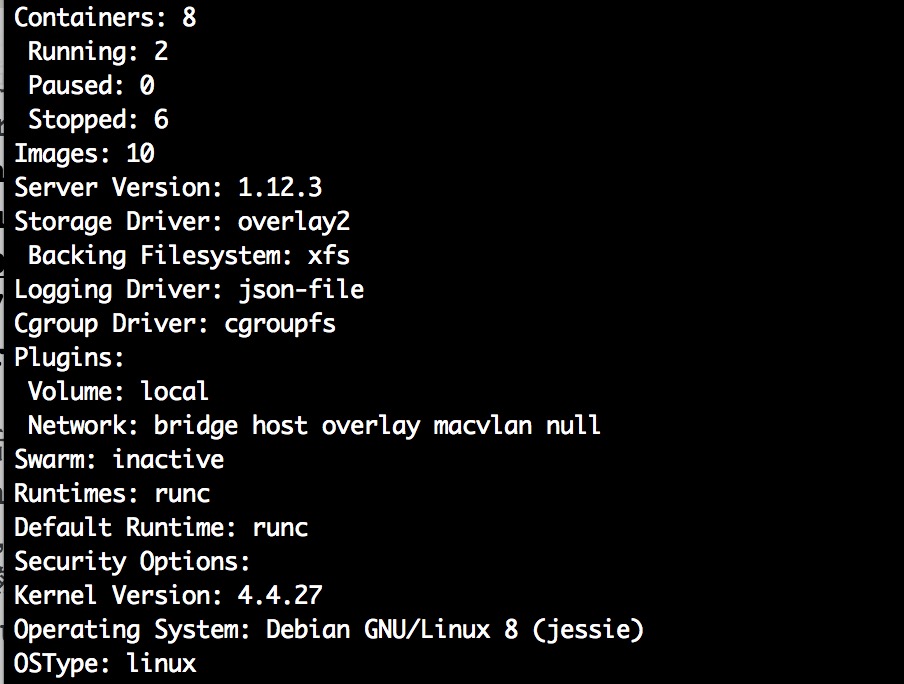
背景
我们线上是物理机,Debian 8 jessie,xfs文件系统,然后内核升级到了4.4.27,
并且docker用的是overlay2,我们使用cadvisor + prometheus对docker宿主机、容器做了监控和告警。
这次故障的现象即是运行一段时间的docker daemon会出现hang住的情况,任何命令,docker info,docker ps均不可用,容器也陷于假死状态,直接重启docker daemon无法恢复.
Workaround方案
我们遇到这样的问题,是出现在版本升级到docker 1.12.3之后(当然,也是因为其他的bug导致我们升级到这个版本的,手动捂脸),鄙人组长随即立马给出了一个workaround方案:
# rm -rf /var/lib/docker/libcontainerd/*
以上命令看似暴力,实则简单有效,每次停掉docker daemon之后,清理该文件夹下面的内容,随即便可以正常启动docker daemon。
当然,这只是workaround,每次这么搞,由于docker daemon本身上面跑了很多应用业务的容器,挂一次也是有宕机成本的。这也就引发了这一次的debug之旅。
思路要清晰
对一个基础组件进行排障时,排障思路一定得清晰。首先,我们得对Docker本身的请求-处理架构有所了解:

debug log & strace it!
很显然,在命令行敲下来的docker命令会首先通过docker client发送给docker daemon,那么是不是docker daemon自身代码出问题了呢?似乎不像,毕竟如果是这样的话,重启应该能恢复,查看docker daemon的log为:
Jun 3 10:38:24 docker-06 dockerd[19722]: time="2017-06-03T10:38:24.167081096+08:00" level=info
msg="libcontainerd: new containerd process, pid: 21057"
Jun 3 10:38:24 docker-06 dockerd[19722]: time="2017-06-03T10:38:24.186999855+08:00" level=debug
msg="containerd: read past events" count=0
Jun 3 10:38:24 docker-06 dockerd[19722]: time="2017-06-03T10:38:24.18737577+08:00"
level=fatal msg=EOF
Okay,不妨用strace确认一下系统调用:
# strace -ff -o log -v docker ps
抓取到的部分日志如下:
getsockname(3, {sa_family=AF_LOCAL, NULL}, [2]) = 0
getpeername(3, {sa_family=AF_LOCAL, sun_path="/var/run/docker.sock"}, [23]) = 0
futex(0xc820046908, FUTEX_WAKE, 1) = 1
read(3, 0xc82036c000, 4096) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(4, {}, 128, 0) = 0
epoll_wait(4, 7ffd0297d8c0, 128, -1) = -1 EINTR (Interrupted system call)
--- SIGWINCH {si_signo=SIGWINCH, si_code=SI_KERNEL} ---
rt_sigreturn() = -1 EINTR (Interrupted system call)
epoll_wait(4, 7ffd0297d8c0, 128, -1) = -1 EINTR (Interrupted system call)
futex(0xc820046908, FUTEX_WAIT, 0, NULL) = -1 EAGAIN (Resource temporarily unavailable)
futex(0xc820046908, FUTEX_WAIT, 0, NULL) = 0
select(0, NULL, NULL, NULL, {0, 100}) = 0 (Timeout)
futex(0xc820046908, FUTEX_WAIT, 0, NULL) = 0
epoll_wait(4, {{EPOLLOUT, {u32=1706739960, u64=140219504052472}}}, 128, 0) = 1
futex(0xc820046d08, FUTEX_WAKE, 1) = 1
mmap(NULL, 262144, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f8765b5e000
write(3, "GET /v1.24/containers/json HTTP/"..., 95) = 95
futex(0xc820046d08, FUTEX_WAKE, 1) = 1
futex(0xc820046908, FUTEX_WAIT, 0, NULL <unfinished ...>
查了一下,FUTEX_WAIT简单说就是当前线程正在等待其他人完成一件事情然后给它反馈,但是很可惜,并没有等到。
BTW, strace命令本身也值得掌握,对于排障很实用,可以参考:这篇文章,也很感谢以前Thomas和俊哥让我学到这条命令。
goroutine dump?
OKay,那么有没有其他办法呢?docker本质上也是一款golang编写的系统软件,那是不是可以做一些堆栈级别的dump来分析呢?谷歌了一下,发现还真有,而且还是官方文档写的(最近莫名其妙收了一个徒弟,我也跟这位同学经常强调,多看官方文档,想不到自己也中招…)!
试试看:
# kill -SIGUSR1 $(pidof dockerd)
fu**… 没能在docker的daemon log里看到任何额外的输出,鄙人甚至以为是自己姿势错了,找了一台正常的docker daemon试了下,的确是有=== BEGIN goroutine stack dump...这样类似的输出,找了下代码,似乎也就是利用golang的runtime包dump出堆栈。
但是,为啥连stack都无法dump呢?而且鄙人在重试重启docker daemon的时候卡在启动过程,而且发送SIGUSR1也无法做dump,what the fuck???
诸般方案都失败的情况下,那还能咋办?鄙人回忆起了最开始看到的docker daemon的log输出,这里再贴一下:
Jun 3 10:38:24 docker-06 dockerd[19722]: time="2017-06-03T10:38:24.167081096+08:00" level=info
msg="libcontainerd: new containerd process, pid: 21057"
Jun 3 10:38:24 docker-06 dockerd[19722]: time="2017-06-03T10:38:24.186999855+08:00" level=debug
msg="containerd: read past events" count=0
Jun 3 10:38:24 docker-06 dockerd[19722]: time="2017-06-03T10:38:24.18737577+08:00"
level=fatal msg=EOF
嗯哼,在libcontainerd new出来containerd的进程之后,出现了EOF的fatal信息,之前怎么没看到这个重要的信息呢?那么,是否是containerd的问题?我们来一探究竟。
根据日志分析启动问题
Okay,第一条libcontainerd的日志位置出现在这里,很显然,它是要做containerd,即容器runtime的boot up,请注意,接下来就是坑点了,再翻一下docker daemon的启动对应代码,你会发现,对libcontainerd建立远程通信,是放在daemon初始化之前的!这也可以解释为啥dump无法生效了,因为它就是在NewDaemon方法里做的啊,喂!
事情似乎又回到了原点,唯一的进展便是,可能libcontainerd本身runtime出问题了,这也可以解释我们删除libcontainerd的数据便能恢复启动的现象。那么再去看看libcontainerd的情况?
继续扒源码
继续上Github翻containerd的源码(吐槽一下Docker官方,仓库位置都挪了,闹哪样!),还记得异常启动的daemon日志里containerd: read past events这一段吗?
似乎像是libcontainerd想要恢复曾经启动过的容器,然后读取之前的历史event,那么这段代码具体在哪呢?Woot!它是containerd启动自己的容器进程管理器supervisor时做的初始化事情里的一部分。
它接下来会做什么?作为程序猿 + 工程师的嗅觉,恩,想来应该是我所猜测的恢复操作,果然不假,代码确实是这样的逻辑。事到如今,再想扒下去,难度就更大了。鄙人突然想到,咦,新版本的containerd有没有改进呢?
亘古不变的解题窍门
mmp! 查到了这样的PR,甚至于supervisor的代码在新版都有了大的变动:
再见!不想再查下去了!果然还是古人说得好哇,对付Docker有两个办法:
#1 升级kernel
#2 升级docker daemon
如果不行的话,就试试两个都升级!恩!鄙人打算先尝试升级下docker daemon(及containerd),以观后效。
结语
鄙人之所以编写这篇“失败的排障之旅”,也是希望能通过鄙人失败的经历,为大家讲述,“我是如何排障docker的”,这些方法理论上来说应该是普遍适用的,strace、debug level log、dump、sourcode level debug,这些都是深入排障一个很tricky的问题时必备的技能。当然,如果各路大神有一些好的建议和吐槽我菜比的地方,欢迎邮箱联系:wjx_colstu@hotmail.com
希望能有所价值!
BTW,Enjoy the container trip!
Colstuwjx
2017.06.03