
[ 原创 ] Saltstack 高可用架构漫谈
这篇文章记录了鄙人折腾Salt项目的背景和一些成果及经验教训。
起因
鄙人折腾Salt也已经一年有余了,从最开始Linux运维的基础知识,包括啥叫配置管理都一无所知,事到如今好歹也做了一些事情,虽然没啥功劳,也埋了一些坑,但是总归在自动化方面贡献了一些微薄的力量。
为什么要搞Salt高可用架构呢? 起因是因为公司内部对于Salt的要求从工具上升到了基础架构组件的层面,要求在响应时间和服务可用性方面有一些更高的要求,简单来说,就是内部的一些重要组件依赖于它来完成一些事情。而Salt原生是默认的单点Master - Minion结构,其Salt-API也是Daemon方式的裸奔运行,我们踩了很多坑,发现实在是痛的不行,鄙人向领导反馈了这一严重隐患,终于也就有了这样的一次折腾。
至今,我们研究的成果已经推广到了生产环境,虽然它还是有很多的问题,然而之所以写下这篇博客,实在只是为了聊以纪念一下整个项目团队几个月来的共同努力。
启发
Salt 高可用架构方面的文档和参考案例还是相当稀少的,直到今年(2015)的5月份左右的样子,才看到官方有整理出一篇高可用相关的文档:https://docs.saltstack.com/en/latest/topics/highavailability/index.html
而这里面讲的也还是比较宽泛,可以选择的架构以及对应的优缺点信息都比较稀少。好在开源大牛们从来都不缺乏分享的精神,鄙人挖了一下SaltConf15上一些成功的案例分享,最主要的当然是Linkedin的Thomas Jackson大牛的分享,最终通过反复研究,有些收获(期间多亏Kenny的几次指点,真的非常感谢)。
MultiSyndic、MultiMaster、Failover Minion、Ext Job Cache
我们这边最后采用的架构采用了MultiSyndic + MultiMaster + Failover Minion这几个salt原生的重要特性,为了不让读者们困惑,这里先首先讲解下这几个特性。
MultiMaster
应该算是最早被引入Salt的一个高可用特性,它允许master设置为一个list,并且任一master均可以ping通所有管辖的minion,这一架构要求master共享一些必要的文件,最好配置文件也共享方式管理,具体配置,各位可以转到官方文档来实验一二。
这一个特性的优势在于它是多主结构,挂掉任意一台都不影响整体的调用(值得一提的是,minion启动的时候是需要连通所有的master才能工作的)。
MultiSyndic
MultiSyndic 是 2014.7版本以后才引入的一个重要特性,它使得SYndic架构变得更加灵活,即一台SYndic可以同时被多台MOfM管理(你可以理解为MultiSyndic的MultiMaster),官方文档这方面做的还不是很完善,只是简单的介绍了一下该如何配置,大家可以看看:https://docs.saltstack.com/en/latest/topics/topology/syndic.html
具体的源码则是放到了minion.py的这一块,本身原理便是MultiSYndic会去复用一些Syndic的功能,然后做一些转发的处理。
MultiSyndic的配置其实有点综合MultiMaster,你需要设置syndic本身的一些配置,包括每台syndic设置syndic_master为一个list mofm,另外Key等文件做共享配置,其次写入一些必要的syndic本身的配置,由于过于细节,这里不再赘述。
Failover Minion(Or MultiMinion)
Failover Minion 则是Salt引入的一个Minion端实现的特性,它允许minion定期的去探测当前master的存活性,一旦发现master不可用,可以在一定时间内做出切换,从而提高整体服务调用的可用性,具体的配置文档也可以参见官方文档,需要注意的是配置MultiMaster 亦或是 MultiMaster PKI都可以使用failover特性,这一点已经由官方强调过,minion配置内容如下:
# multi-master
master:
- 172.16.0.10
- 172.16.0.11
- 172.16.0.12
# 设置为failover minion
master_type: failover
# 设置启动时随机选择一台master
master_shuffle: True
# 探测master是否存活的schedule job
# 即使用salt schedule特性实现的功能
master_alive_interval: <seconds>
Ext Job Cache
如何分解出master的压力?一方面,可以做负载均衡,将minion分散到不同的Master去管理,另外一方面,跑salt-job的主要需求还是获取job结果,为了减轻查询结果方面的压力,也为了提高整体架构的并发能力,鄙人推荐了引入ext job cache的特性。
实际上,使用ext_job_cache配置搭配合适的returner便可以让salt-master默认将job数据写入到指定的存储,然而这样带来的坏处是一旦你存储的组件挂掉了,比如配的redis returner,redis一旦挂掉,那么job便根本无法下发(因为job下发的时候便会将job load写入到cache,即这次job的执行参数和命中的具体minion数据),为了规避这一个坑,鄙人改造了绿肥同学基于Salt Event系统构建Master端returner这篇博客里讲解的监听event并写入job数据的方案,通过配置额外的服务来实现了ext job cache的写入。
几种高可用架构的选择
OK,至此,我们已经了解了一些基本的Salt原生提供的高可用特性,接下来,鄙人将为您分享我个人认为不同的量级和场景下推荐的Salt高可用架构方案。
备注:这里统一建议一下salt-master的配置性能,我个人之前使用的salt-master是2C6G的低配虚拟机,踩了非常多的坑,包括Auth风暴等等,1k台机器之后使用起来体验也相当糟糕,所以个人建议salt-master配置至少> 8C的计算能力~
方案1: Single Master With Warm Backup
适用场景:< 1k Minion的小规模应用
Salt版本限制:印象中至少0.17已经支持了这个特性
问题:我个人也没有在生产具体应用过该架构,但是
SaltConf15上已有这样的用例,应该是完备的一方案~
Salt 原生支持salt-master指向配置成DNS域名,它会通过resolv_dns函数来解析具体的master ip,所以在minion发现与master中断后,它会尝试和master重新连接,而可以通过重新解析DNS来实现Master的切换。
方案2:MultiMaster
适用场景: 1k ~ 4k,调用强度集中于小规模机器
鄙人也和几位业内的运维交流了salt的一些心得,应该目前来说,MultiMaster算是最常见的应用架构,它足够的简单,并且Salt原生的支持也相对比较成熟,个人也推荐在中等规模及一般使用的情况下可以使用这样的一个架构来满足需求。
方案3:MultiMaster + MultiSYndic + FailoverMinion(linkedin分享的架构#5)
适用场景:并发调用强度相对较高,并且分多套salt各自维护(比如UAT和PROD不是一个团队的人来维护这样一个情况),
对于salt服务的SLA以及性能方面有较高要求的场景,机器数量方面可以通过横向扩展来解决,
一般来说,建议 ~10k 及以上的规模采用此架构方案(并且鄙人尝试配置过官方原生的这个架构,
貌似有很多的坑,我们这边是通过修改了MultiSyndic的部分代码才使得整体架构可用)
话不多说,一图胜千言,实际上,我们内部用的就是linkedin分享的第5套架构,可能有人会问,为啥不用第6套架构呢? 我个人测试过,第6套架构是可行的,但是貌似只能跑两台master互为master\syndic,一旦配成三台便会出现event loop,这个我们内部分析过,应该是一个合理的逻辑,不知道为啥linkedin最终是推荐的这个架构?
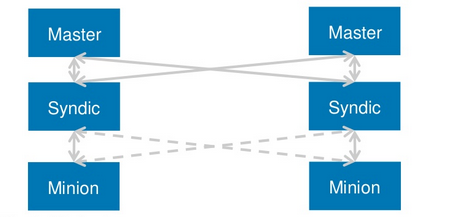
采用这一架构的话,首先一点,我们可以在MofM这一层架设Salt-API,并设置负载均衡,这样一来的话,能实现API这一层的负载均衡及横向扩展。另外一方面,MultiSyndic这一层,由于每台minion实际一个时刻只由一台SYndic Master管理,因此Syndic Master的压力被分散到了每台机器上,再者,MofM由于可以和所有的SYndic通信,因而上层的Salt-API可以ping通全量的Minion!值得补充的是,我们将syndic的job event额外吐到了统一的redis job cache,这样一来,通过调整salt api的调用方式(从同步改成异步),即可极大的减轻Master的负载,将压力均摊到了redis cache(减少了大量的find_job任务,当然,问题即在于你必须给出一个大致的超时时间,因为问询salt-minion是否完成的逻辑改成了query job cache,所以无法感知minion实际是否真的在执行与否)。
如此一来,即实现了负载均衡 + 高可用 + 可横向扩展的Salt架构方案!Success!
当前架构的利与弊
通过生产环境的线上实际体验,我们也获知了我们当前采取的#5架构的一些具体的利弊所在,不敢私藏,在此分享一二。
利
这一架构的优势在于高并发的爆发能力和可扩展的负载均衡能力。
首先,我们用nginx + UWSGI将salt-api封装了一层,使得其并发能力和稳定性有了一定的提高。
另外, 这个架构下,上层MofM只负责下发Job并且可以横向扩展,这便实现了强大的API高并发的可能,另外, Syndic每台管理1/n的minion机器,相对的负载被分散到了各台机器上,理论上来说它可以支撑的minion机器规模是足够数量级的。
弊
诶,这个架构目前的劣势也是相当的明显,成也MultiSyndic,败也MultiSyndic, Syndic的逻辑是处理完结果后会把job数据回吐给MofM,而MofM理论上是可以ping通所有minion的,所以一旦执行类似Salt * test.ping命令的时候,MofM就等于承受了一次短时间的数据流量的冲击,所有Syndic会在短时间内把job result回吐给MofM,1w台minion便是1w条minion job数据,再加上find_job任务,后果不堪设想..
因此,我们如今也在推动整改成异步调用的方式,并且也在思考如何优化这一层的处理,实际上,用户如何使用也是一个很大的哲学。
结语
这篇文章是鄙人今天整理这几个月的感受仓促而成,很多的细节还没有完全的揭露,实际上,生产环境的线上考验仍然不够充分,然而,毕竟还是完成了一个小小的milestone,写出这篇文章,也是为了分享一下个人的踩坑记。Salt的确很坑,有很多的问题, 但是,在决定使用它并将其作为基础架构组件的情况下,抱怨变得毫无意义,如何有方法的具体的去实施,去解决问题才是我们实际需要考虑的事情。
在这几个月的过程中,从最开始的茫然,焦躁,到在Kenny带领下研究架构的方案,再到找上Dingw大哥一起研究和改动MultiSYndic的代码,实在是成长了很多,多亏了几位大哥的帮扶,尤其是Kenny, Dingw,Bshu, JY 几位大哥,在架构和代码二次开发方面出了很多力气,鄙人也算是在几位大哥的carry下算是一起完成了这件事情罢。目前,只是完成了新架构的生产切换,未来可能还会有很多的挑战,鄙人很遗憾后续无法更多的参与,但是很感恩与团队里的同事们一起攻克问题的这几个月的经历。
这个架构是否可以完全适应我们公司内部的使用也有待进一步的考验,也相信我们项目团队会进一步的优化和改善Salt的使用,最终促成一个健壮的Salt基础架构组件服务!!
谨以此文纪念鄙人职业生涯第一次加入一个团队,由大哥们带领一起完成的一件小事。
完。
原文源自:http://devopstarter.info/saltstack-ha-arch/ 烦请尊重原创,注明出处,谢谢!